



发布时间:2021-07-27 10: 34: 13
近些年AI人工智能领域发展的如火如荼,图像识别、语音识别等功能都陆续地被开发和应用,并发挥着巨大的作用,逐步便利人们生活的各方各面。语音识别常用于将语音转换为文字,用途广泛,在翻译、聊天、视频制作中都能随处见到它的身影。
Camtasia是一款Windows系统上的录屏和视频编辑制作软件,那么这种软件,非常必要的功能就是字幕添加功能,今天我们就使用它内置的语音识别功能,来学习快速制作字幕。
一、训练语音模型
我们首先在轨道上导入一段要输入字幕的视频,然后选择此视频,点击左侧列表的“字幕”,点击设置图标按钮,选择“语音到文本”。
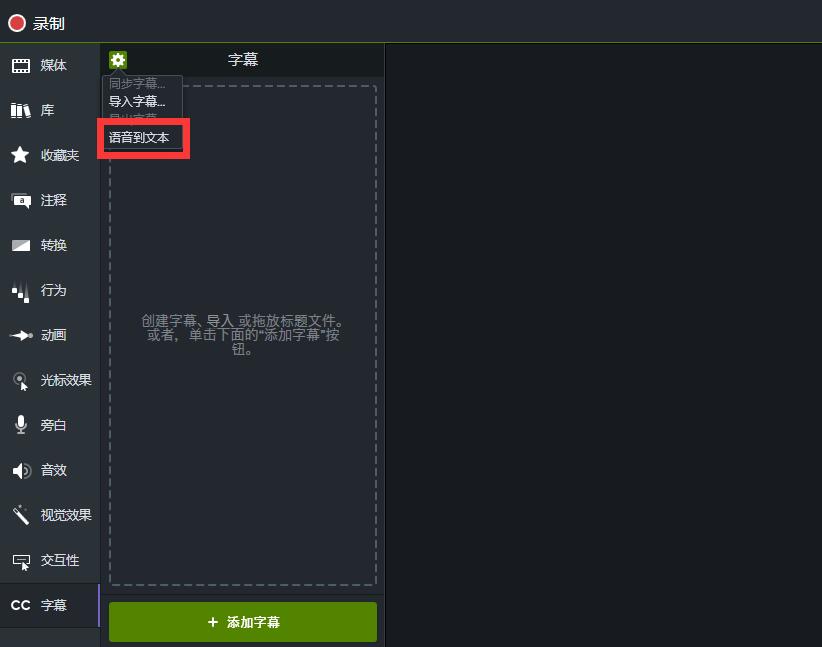
Camtasia会提示我们它需要通过麦克风,录制我们特定某段对话的声音,进而训练出相符合的语音模型。
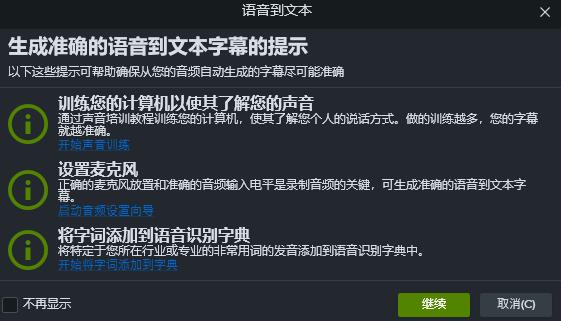
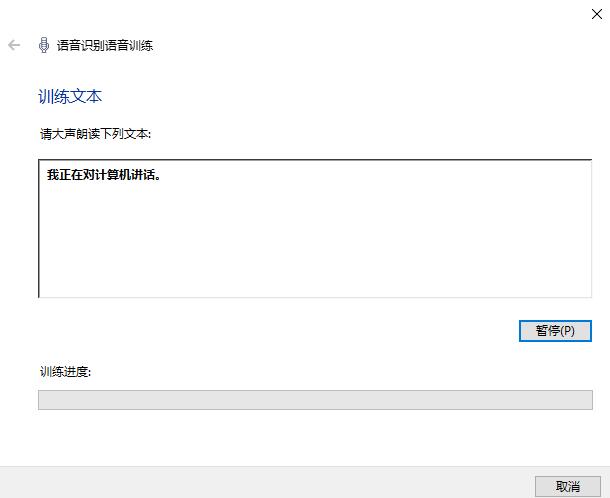
我们点击蓝色字体的“开始声音训练”,进入语音识别语音训练界面,然后对着给定的某段文本进行朗读,如下图3的“我正在对计算机讲话”。
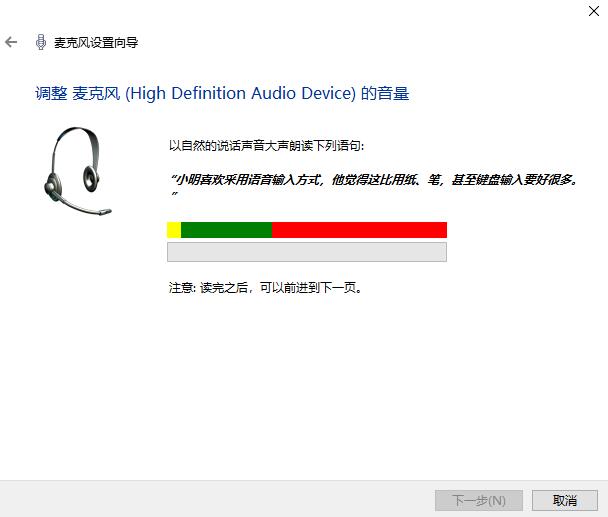
下面我们需要点击“启动音频设置向导”,设置麦克风的及音频输入的大小,以便于更好地提高音频识别模型的训练准确率。
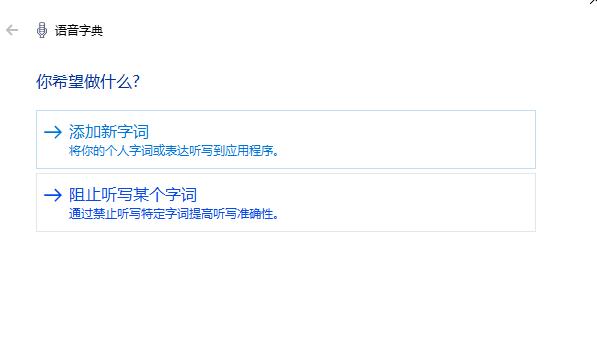
如果我们有一些特殊的行业用词需要进行识别或不需要进行识别,那么此时我们就需要点击“开始将字词添加到字典”,进行字词的添加。我们可以选择添加进行识别或者是阻止听写,如图5。
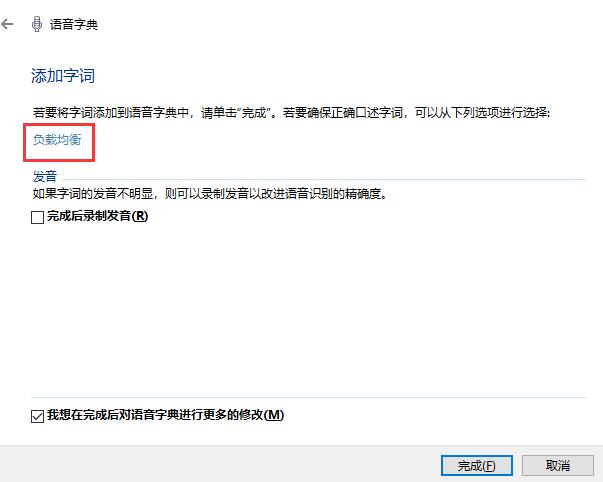
随后将我们要添加的专业性词汇输入到输入框中,如“负载均衡”,再点击下一步,如果字词的发音不明显,我们需要勾选“完成后录制发音”,对该词语进行专门的发音录制。
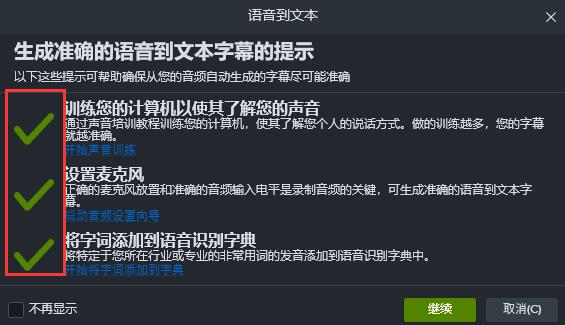
上述设置全部完成以后,提示界面左侧会全部变为勾选图标,具体见图7,此时我们点击“继续”,开始将视频中的音频识别转换为文本。
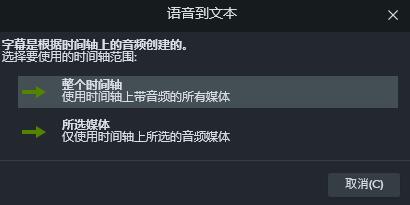
二、识别音频
开始识别时,我们需要选择录制音频的范围,可以是某段媒体视频,也可以是整个时间轴的所有媒体。
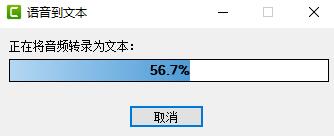
选择完成后,我们只需要等待Camtasia帮我们将音频转录为文本即可。
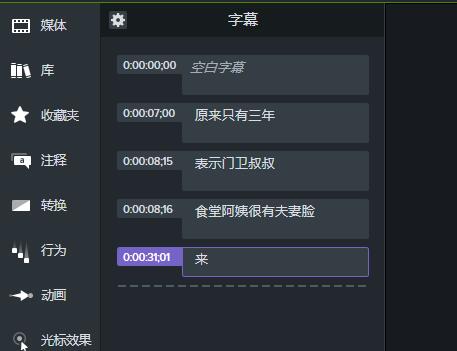
转换成功后结果见图10,Camtasia不仅帮我们进行了语音的识别转换,更好的地方在于它还帮我们进行音频时间点的匹配,我们下面只需要对识别错误的地方进行手动更正就可以了。
上述就是关于Camtasia的语音转换为字幕功能的相关教程,Camtasia提供了通用的和专用的语音训练功能,帮助我们更好地对音频进行识别转换,当我们训练好相关的音频模型后,之后就可以一劳永逸,非常方便地进行字幕的添加了。
作者署名:包纸
展开阅读全文
︾
产品
支持
关于
联系客服
Copyright © 2025 Camtasia 苏州思杰马克丁软件有限公司 经营许可证编号:苏B1.B2-20150228| 证照信息 特聘法律顾问:江苏政纬律师事务所 宋红波




 400-8765-888
400-8765-888
